DisenHAN 논문 리뷰: 요인을 분리하여 더 똑똑한 추천 시스템 만들기
쩝쩝LAB의 ‘취향과 상황에 맞는 레스토랑 추천 시스템’을 위한 그래프 기반 모델 리뷰
쩝쩝LAB의 ‘취향과 상황에 맞는 레스토랑 추천 시스템’을 위한 그래프 기반 모델 리뷰
1. 왜 이 논문을 리뷰하게 되었는가?
쩝쩝LAB에서는 사용자마다의 다양한 취향(예: 맛, 양, 분위기)과 상황(예: 혼밥, 데이트, 회식 등)을 고려한 레스토랑 추천 시스템을 만들고자 합니다. 이를 위해 단순한 협업 필터링을 넘어서 사용자-음식점-키워드 간의 복잡한 관계를 모델링할 수 있는 이종 그래프 기반 추천 모델을 탐색 중입니다.
이런 맥락에서, 의미적 요인을 분리해 해석 가능한 추천 결과를 만들어주는 모델인 DisenHAN을 리뷰하게 되었습니다.
2. DisenHAN이 해결하고자 하는 문제
기존 GNN 기반 추천 모델들은 다양한 관계(예: 구매, 리뷰, 태그 등)를 하나의 임베딩 공간에 뭉뚱그려 표현합니다. 이로 인해 다음과 같은 문제가 발생합니다:
- 각 관계가 가지는 의미적 차이를 구별하지 못함
- 모델의 해석 가능성 부족 → 왜 추천되었는지 설명하기 어려움
DisenHAN은 이러한 한계를 해결하고자 다음과 같은 질문에서 출발합니다
“각 관계는 서로 다른 의미를 갖는데, 이를 분리하여 표현할 수는 없을까?”
2-1. 의미 분리 후 결합하는 문제 및 해결법
DisenHAN은 사용자와 아이템 노드의 표현을 다양한 의미적 측면(aspect)을 하위공간(subspace)으로 분리함으로써, 각기 다른 관점에서 사용자 선호와 아이템 특성을 정밀하게 파악하려는 목표를 갖습니다. 하지만 의미 분리를 수행한 뒤에는 새로운 문제가 발생합니다. ‘분리된 각 하위공간에서의 표현들을 어떻게 정합성 있게 결합할 것인가’ 입니다. 특히 이종 그래프에서는 다양한 메타 관계가 존재하고, 각 관계가 특정 하위 공간에서 서로 다른 중요도로 영향을 미칠 수 있기 때문에 단순 평균이나 고정된 가중치로는 의미 있는 결합은 어렵습니다.
이를 해결하기 위해 DisenHAN은 Graph Attention Network(GAT)에서 도입된 attention 구조를 바탕으로 하되, 이를 이종 그래프(Heterogeneous Graph)와 다중 의미 측면(Multi-Aspect)에 맞게 구조적으로 확장한 새로운 설계를 제시합니다.
먼저, 기존 GAT는 동일한 노드 타입과 관계를 전제로 모든 이웃 노드에 대해 하나의 attention score를 학습합니다. 반면 DisenHAN은 메타 관계별로 이웃 노드를 구분하고, 각 메타 관계가 각 의미 측면에 얼마나 중요한지를 별도로 학습합니다. 즉, attention weight가 단일 차원이 아닌, 관계 × 측면이라는 이차원적인 soft attention 구조를 가집니다.
이 과정에서 DisenHAN은 메타 패스를 사전에 수작업으로 정의할 필요 없이, 메타 관계 단위로 의미 정보를 분해하고 자동으로 재조합합니다. 이는 곧 자동 메타 관계 구성(Auto Meta-Relation Construction)으로 이어지며, 의미 측면과 관계 유형 간의 동적 상호작용을 학습 가능한 파라미터로 처리할 수 있게 합니다.
또한 이러한 구조는 확장성 측면에서도 매우 유리합니다. 새로운 관계 유형이 등장하거나 의미적 분류 체계가 확장되더라도, 기존 모델 구조를 바꾸지 않고 attention weight만 재학습하면 쉽게 결합할 수 있습니다. 결국 DisenHAN은 GAT의 attention 메커니즘을 기반으로, 관계-하위공간별 정렬과 집계를 가능케 하는 방향으로 진화시킨 모델로서, 의미 분리와 결합이라는 이중 과제를 효과적으로 해결하며, 해석 가능성과 확장성 면에서도 높은 장점을 보입니다.
3. 모델 구조 한눈에 보기
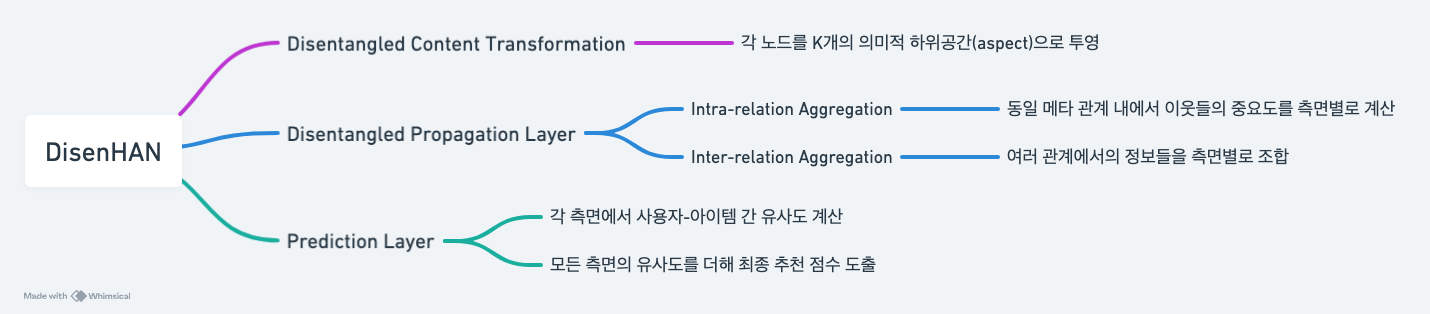
DisenHAN은 세 가지 주요 단계로 구성됩니다:
- Disentangled Content Transformation:
- 각 노드를 K개의 의미적 하위공간(subspace)으로 투영
- Disentangled Propagation Layer
- Intra-relation Aggregation: 동일 메타 관계 내에서 이웃들의 중요도를 하위 공간별로 계산
- Inter-relation Aggregation: 여러 관계에서의 정보들을 하위 공간별로 조합
- Prediction Layer:
- 각 하위 공간에서 사용자-아이템 간 유사도를 계산하고, 이를 모두 더해 최종 추천 점수 도출
📐 주요 수식 요약 및 설명
Disentangled Content Transformation (요인 분리 임베딩 투영)
노드 특성의 하위 공간별 투영 \[ct,k = \frac{\sigma(W_{\phi(t),k} \cdot x_t)}{\|\sigma(W_{\phi(t),k} \cdot x_t)\|_2}\]
각 노드는 다양한 타입과 특성을 가지므로, 먼저 타입별로 노드의 속성 벡터를 K개의 하위 공간 subspace에 투영하여 초기 임베딩을 구성합니다.
- \(x_t\): 노드 \(t\)의 원본 특성 벡터
- \(W_{\phi(t),k}\): 노드 타입 \(\phi(t)\)와 하위 공간 \(k\)에 따른 투영 행렬
- \(c_{t,k}\): 노드 \(t\)의 하위 공간 \(k\)에 대한 정규화된 표현
- \(\sigma\): 비선형 함수 (예: ReLU)
Intra-relation Aggregation (메타 관계 내 집계)
하위 공간별 이웃 중요도 계산 \[e^k_{t,s} = \text{ReLU}(\alpha^T_{\psi(e)} [z^{(i-1)}_{t,k} \| c_{s,k}])\]
: 메타 관계 \(\psi(e)\) 내에서, 타깃 노드 t와 이웃 노드 s 간의 의미적 중요도를 하위 공간 k별로 계산
모든 하위 공간에 대한 가중 합산 중요도 \[e^{\psi(e)}_{t,s} = \sum_{k=1}^K r^{(i-1)}_{\psi(e),k} \cdot e^k_{t,s}\]
: 각 하위 공간의 중요도 r를 곱해 이웃의 최종 중요도를 통합
정규화된 attention weight 계산 \[\alpha^{\psi(e)}_{t,s} = \frac{\exp(e^{\psi(e)}_{t,s})}{\sum_{s’ \in N_{\psi(e)}} \exp(e^{\psi(e)}_{t,s’})}\]
이웃 노드 정보 집계 (각 하위 공간별로) \[z^{\psi(e)}_{t,k} = \sigma\left(\sum_{s \in N_{\psi(e)}} \alpha^{\psi(e)}_{t,s} \cdot c_{s,k} \right)\]
Inter-relation Aggregation (관계 간 의미 통합)
\[z^{(i)}_{t,k} = \frac{c_{t,k} + \sum_{\psi(e) \in \Psi_t} r^{(i)}_{\psi(e),k} W z^{\psi(e)}_{t,k}}{\left\| c_{t,k} + \sum_{\psi(e) \in \Psi_t} r^{(i)}_{\psi(e),k} W z^{\psi(e)}_{t,k} \right\|_2}\]- \(r^{(i)}_{\psi(e),k}\): 메타 관계 \(\psi(e)\)의 하위 공간 \(k\)에 대한 중요도
- \(W\): 임베딩 공간 정합을 위한 선형 변환 행렬
- \(c_{t,k}\): 현재 타깃 노드의 하위 공간별 초기 표현
이 과정을 통해 노드는 반복적으로 각 메타 관계의 의미 정보를 하위 공간별로 모으고, 이로 인해 해석 가능하고 정교한 추천 임베딩이 만들어집니다.
Prediction Layer (추천 점수 계산)
최종적으로, 각 사용자–아이템 쌍에 대해 하위 공간별 내적을 통해 추천 점수를 계산합니다.
유사도 기반 추천 점수 \[s_{uv} = \sum_{k=1}^K z^T_{u,k} \cdot z_{v,k}\]
- \(z_{u,k}\), \(z_{v,k}\): 학습된 사용자/아이템의 하위 공간별 임베딩
확률 변환 (implicit feedback 예측용) \[y_{uv} = \frac{1}{1 + e^{-s_{uv}}}\]
- 시그모이드 함수를 통해 예측 확률로 변환 (사용자 \(u\)가 아이템 \(v\)에 관심 가질 확률)
4. 실험 결과 및 인사이트
RQ1. DisenHAN은 기존 SOTA 모델보다 얼마나 잘 작동하는가?
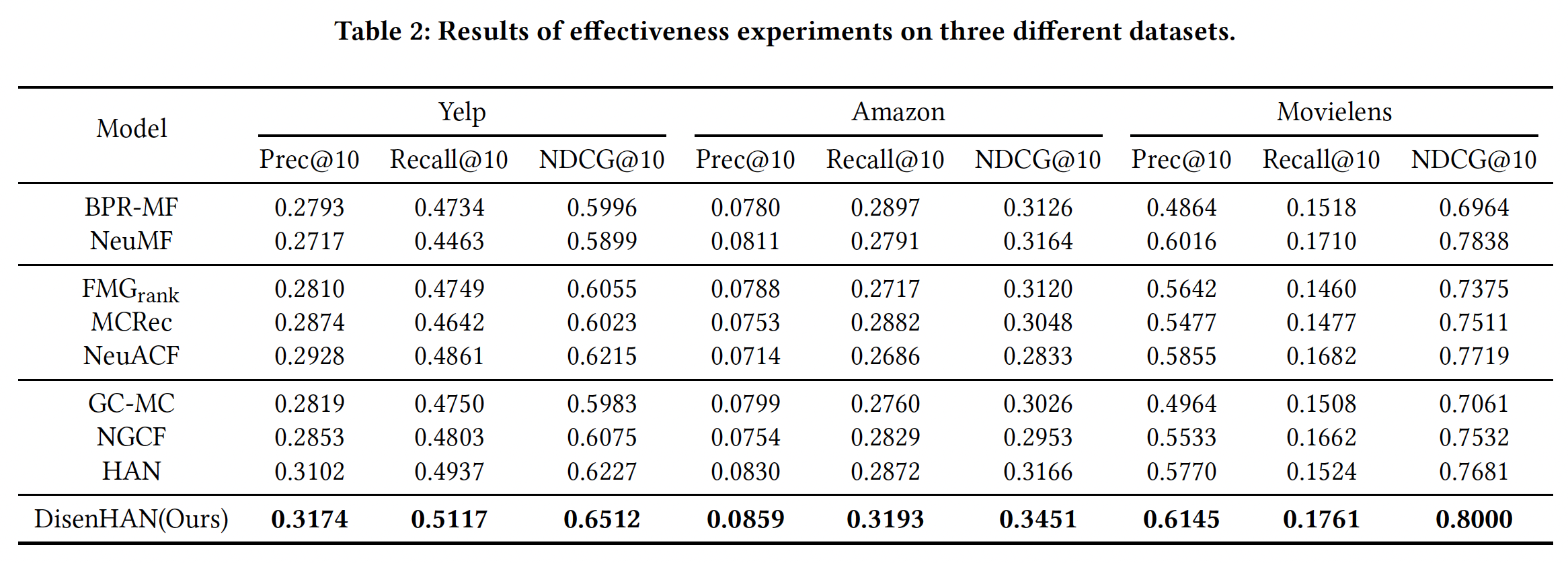
정량적 비교 결과 (Table 2 기준)
- DisenHAN은 Yelp, Amazon, MovieLens 모든 데이터셋에서 Prec@10, Recall@10, NDCG@10 지표에서 기존 SOTA를 모두 능가함
- 특히 강력한 GNN 기반인 HAN, NGCF보다도 명확한 우위
성능 향상 요인 요약
- 기존 HIN 기반 모델은 수작업 meta-path 설계에 의존 (도메인 지식 필요)
- GNN 기반 모델은 고차 연결은 활용하지만 의미적 분리 미흡
DisenHAN은 meta relation을 통해 고차 연결성과 의미 요인을 동시에 학습
→ 해석 가능 + 추천 성능 향상
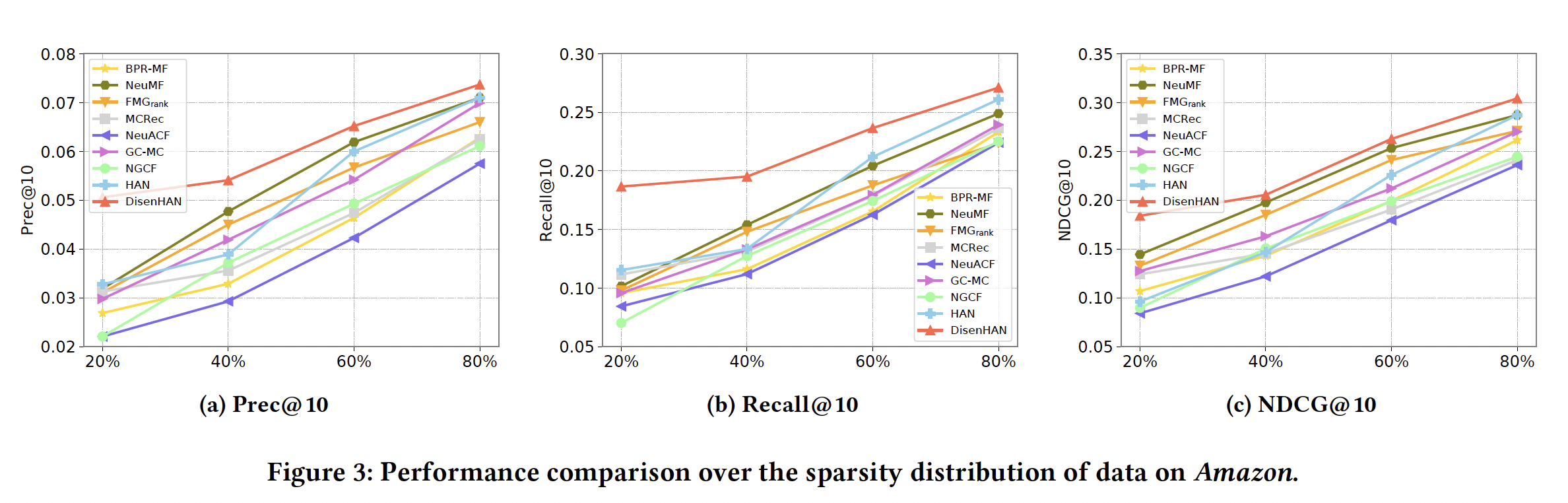
RQ2. DisenHAN 구조의 핵심 요소들이 실제로 중요한가?
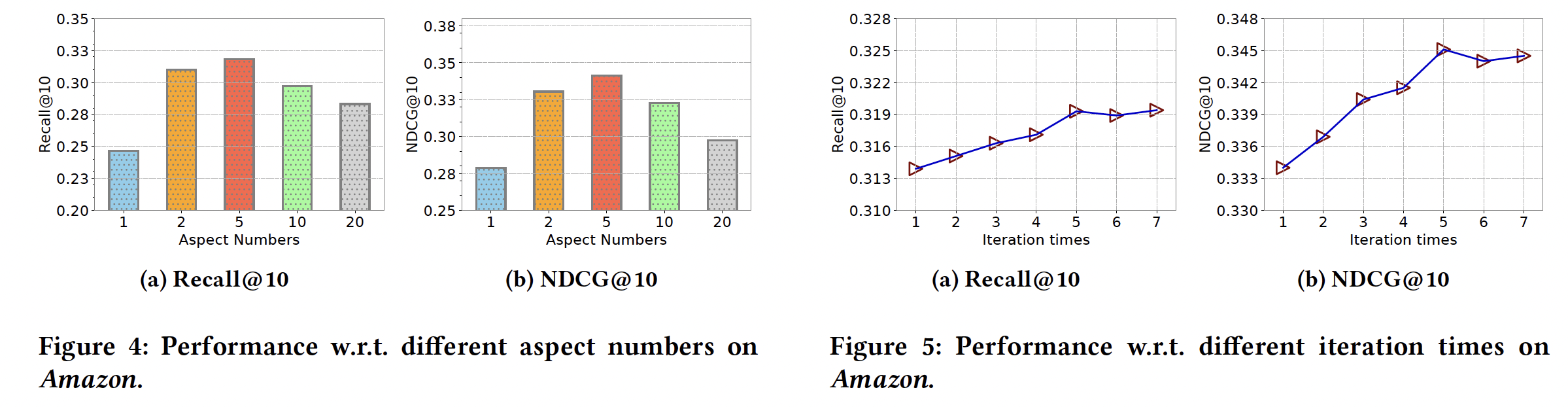
① Disentangled Representation 효과
- Aspect 수를 1, 2, 5, 10으로 바꿔가며 실험
- Aspect 수가 1일 때는 일반 HIN-GNN과 동일 → 성능 낮음
- Aspect 수가 5일 때 가장 성능 우수 → 실제 의미 요인 수와 유사할 때 효과 큼
② Iteration 횟수 효과
- 반복 횟수 1~7까지 변화
- 5 이상이면 성능 변화 미미 → 5회 반복이 충분함
- 다른 하이퍼파라미터에 비해 sensitive하지 않음
③ 레이어 수 효과
- Layer 1 → 2로 갈수록 성능 향상
- Layer 3에서는 오히려 성능 저하 (overfitting + 노이즈 유입 가능성)
RQ3. DisenHAN은 의미 분리를 실제로 해석 가능한 방식으로 수행하는가?
① 메타 관계별 주요 의미 분석
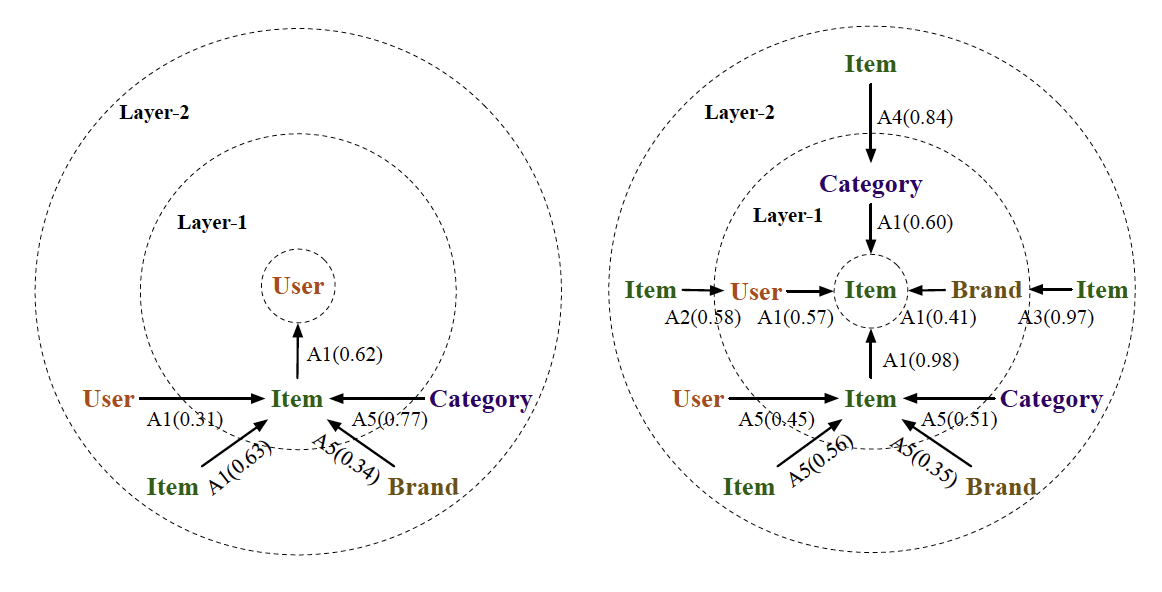
- Amazon 데이터셋을 기준으로, 각 메타 관계가 어떤 aspect와 연결되는지 시각화
- 예: ⟨Item, has Brand⟩ 관계 → Aspect A3
- ⟨Item, has Category⟩ 관계 → Aspect A4
레이어 1에서는 주로 user-item 상호작용 관계 (A1),
레이어 2에서는 item context 관계 중심 (A2, A3, A4)
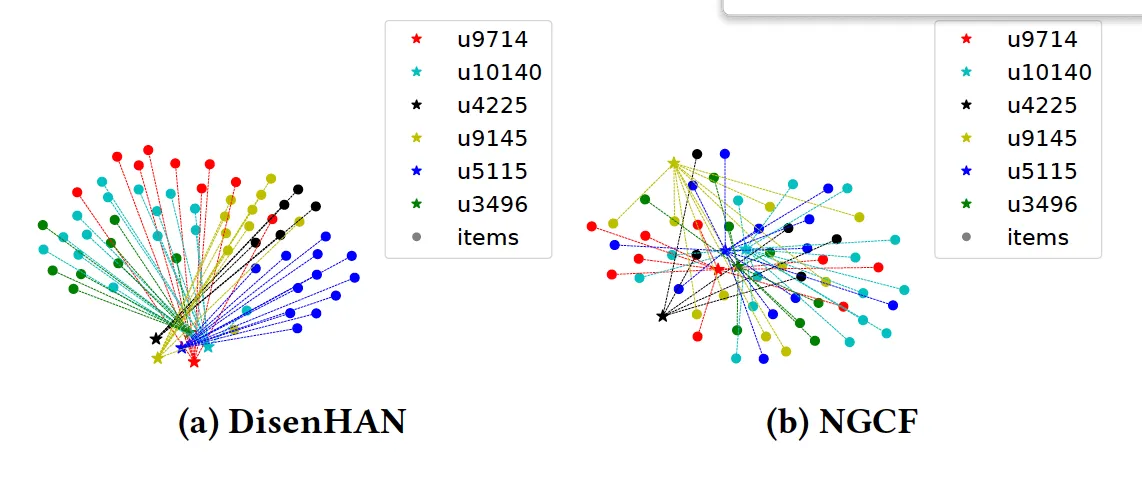
② 임베딩 시각화 비교
- DisenHAN는 NGCF에 비해 유저별로 관련 아이템이 잘 분리되어 클러스터링
5. 쩝쩝LAB에 주는 시사점
💡 DisenHAN이 쩝쩝LAB에 유용한 이유:
- 사용자-음식점-키워드-상황 간의 관계를 이종 그래프로 구성 가능
- 리뷰 키워드를 메타 관계로 활용하여, ‘맛’, ‘가격’, ‘분위기’ 등 의미적 요인으로 자동 분리
- 관계 안의 이웃 노드마다 “어떤 의미에서 중요한지”를 attention으로 학습
- 추천 이유를 하위 공간별로 설명할 수 있어 사용자 설득력 향상 가능
💭 향후 실험 아이디어:
- 사용자의 상황 정보(시간, 날씨, 동행자 등)를 노드/관계로 모델링
- DisenHAN 구조를 기반으로 쩝쩝LAB만의 GNN 실험 프로토타입 구축
6. 마무리하며
DisenHAN은 단순히 성능이 좋은 모델이 아니라, 추천에 있어 의미 요인을 구별하고 해석할 수 있게 해주는 구조라는 점에서 큰 장점이 있습니다.
쩝쩝LAB이 목표하는 “취향과 상황에 맞춘 추천”의 맥락에서, DisenHAN은 그 자체로도 훌륭한 기반 모델이며, 앞으로의 확장 실험에 있어 강력한 출발점이 되어줄 수 있습니다.